

Семплирование данных – это процесс извлечения репрезентативной выборки из большого объема данных с целью анализа и обработки. Оно является важной частью многих аналитических и исследовательских процессов, так как позволяет получить информацию о генеральной совокупности, используя лишь ограниченное количество данных.
Существует несколько основных подходов к семплированию данных. Один из них — простое случайное семплирование, когда каждый объект из генеральной совокупности имеет равные шансы быть выбранным. Другой подход — стратифицированное семплирование, при котором генеральная совокупность делится на несколько страт, а затем из каждой страты случайным образом выбирается определенное количество объектов. Еще один метод — систематическое семплирование, которое предполагает выбор каждого k-го объекта из генеральной совокупности.
Однако несмотря на различные методы семплирования, существуют некоторые проблемы, с которыми можно столкнуться при работе с выборками данных. Например, выборка может быть смещенной, что приведет к искаженным результатам. Также может возникнуть проблема недостаточной размерности выборки, что не позволит получить репрезентативную информацию о генеральной совокупности. Для решения этих проблем важно использовать правильные методы семплирования и учитывать особенности данных, с которыми работаете.
Семплирование данных: что это и как с этим бороться
Борьба с проблемами семплирования данных
- Случайные выборки: Одним из способов борьбы с проблемами семплирования данных является использование случайных выборок. Это позволяет уменьшить смещение выборки и обеспечить репрезентативность данных.
- Стратификация: Стратификация – это распределение выборки на подгруппы с целью улучшения представительности исходных данных. Этот метод позволяет контролировать пропорции данных в выборке и обеспечивает более точные результаты.
- Взвешивание данных: Взвешивание данных – это процесс назначения весов разным элементам выборки в зависимости от их значимости и репрезентативности. Это помогает учесть разные характеристики данных и дает более точные результаты при анализе.
- Кросс-валидация: Кросс-валидация – это метод, который позволяет оценить обобщающую способность модели на основе нескольких неперекрывающихся выборок данных. Это помогает уменьшить риск переобучения и повышает надежность результатов.
Что такое семплирование данных
Существует несколько методов семплирования данных. Одним из самых распространенных методов является случайное семплирование, при котором каждый элемент выборки имеет равную вероятность быть выбранным. Также существуют методы семплирования с весами, когда элементы выборки имеют разные вероятности быть выбранными в зависимости от их значимости или частотности.
Почему семплирование данных важно
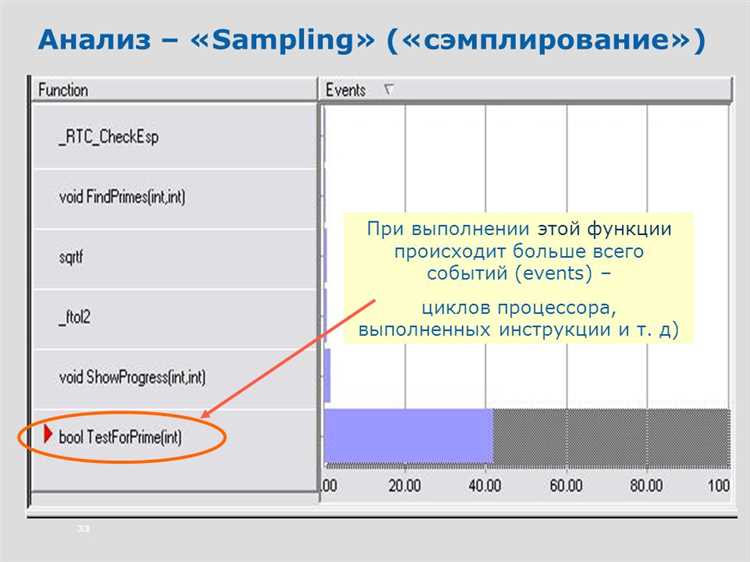
Одной из главных проблем в анализе данных является несбалансированность выборки. Это означает, что некоторые классы данных представлены значительно меньшим количеством примеров, чем другие. В таких случаях модели машинного обучения могут быть склонны предсказывать только доминирующий класс, игнорируя менее представленные классы. Семплирование позволяет создать новую выборку, в которой классы представлены более равномерно, что помогает моделям более точно предсказывать весь спектр классов.
Другой проблемой, с которой сталкиваются исследователи и аналитики данных, является ограниченность доступных данных. В реальной жизни не всегда есть возможность собрать много данных для анализа. В таких случаях семплирование данных позволяет создать искусственные выборки, которые могут быть использованы для обучения моделей. Это особенно полезно в задачах с ограниченным количеством данных, например, в медицинских исследованиях, где доступ к большому объему информации может быть ограничен. Семплирование помогает снизить зависимость от ограниченных данных, позволяя проводить анализ с использованием меньшего объема информации.
Проблемы, связанные с семплированием данных
Одной из основных проблем является искажение статистических свойств семплированной выборки относительно исходной генеральной совокупности. Это может произойти из-за неправильного выбора метода семплирования, нерепрезентативности выборки или неверного представления данных в модели.
Кроме того, семплирование данных может привести к потере информации и точности в результатах. Малый объем выборки может не содержать достаточно разнообразных данных для получения полной картины и не учитывать все факторы, влияющие на объект исследования. В результате, анализ может быть неполным или неточным.
Для решения этих проблем необходимо аккуратно выбирать метод семплирования, учитывать репрезентативность выборки, применять методы коррекции и валидации результатов. Также важно проводить анализ полученных результатов и оценивать их достоверность, учитывая возможные искажения и ошибки, связанные с семплированием данных.
Как бороться с проблемами семплирования данных
Другая проблема связана с несбалансированным набором данных. Если в наборе данных есть классы или категории, представленные очень небольшим числом примеров, модель будет иметь трудности в их определении и может давать неправильные предсказания. Для решения этой проблемы можно применять методы субдискретизации или ансамблирования, которые позволяют объединить данные из разных классов для получения сбалансированного набора данных.
- Аугментация данных — метод, позволяющий расширить набор данных путем создания синтетических примеров путем преобразования существующих данных. Он может быть полезен, когда некоторые классы или категории имеют недостаточно примеров или представлены в данных неравномерно. Например, для изображений это может быть преобразование: поворот, смещение, масштабирование и так далее.
- Субдискретизация — метод, который позволяет уменьшить количество данных в неравномерно представленных классах или категориях путем удаления некоторых примеров. Это может быть полезно для устранения смещения модели и неправильного обучения в случае, когда некоторые классы или категории представлены намного большим числом примеров, чем другие.
- Ансамблирование — метод, позволяющий объединить данные из разных классов или категорий для получения сбалансированного набора данных. Это может быть полезно в случае с несбалансированным набором данных, где некоторые классы или категории представлены очень небольшим числом примеров.
Техники снижения ошибок в семплировании данных
Одной из наиболее распространенных техник является стратифицированное семплирование. При этом данные разбиваются на страты, или группы, и из каждой страты случайным образом выбирается определенное количество элементов. Эта техника позволяет учесть различные группы, представленные в данных, и снизить смещение выборки.
- Пропорциональное стратифицированное семплирование: каждая страта выбирается с учетом ее доли в исходной всей выборке. Например, если в исходной выборке 60% объектов принадлежат к одной страте, то в семпле также будет 60% объектов из этой страты.
- Оптимальное стратифицированное семплирование: страты выбираются таким образом, чтобы минимизировать дисперсию оценки для исследуемого параметра. Эта техника использована во многих научных исследованиях, где точность оценки является особенно важной.
Еще одной техникой снижения ошибок в семплировании данных является использование случайного семплирования с замещением. При этом каждый объект может быть выбран в семпле несколько раз. Такой подход позволяет учесть различные комбинации объектов и повысить точность оценки параметров выборки. Однако, при этом возникает проблема, что некоторые объекты могут быть выбраны слишком часто, что может привести к смещению выборки. Для решения этой проблемы применяется случайное семплирование без замещения, при котором каждый объект может быть выбран только один раз.
Как правильно использовать семплирование данных
Во-первых, необходимо тщательно выбирать методы семплирования данных, основываясь на поставленных задачах и характеристиках исходного набора данных. Разные методы семплирования могут привести к разным результатам, поэтому важно выбрать тот метод, который наилучшим образом соответствует вашим потребностям.
Кроме того, следует помнить о том, что семплирование данных может привести к потере некоторых важных свойств исходной выборки. Поэтому перед использованием семплирования необходимо оценить, насколько качество исходных данных будет сохранено после применения семплирования.